1.AI发展史
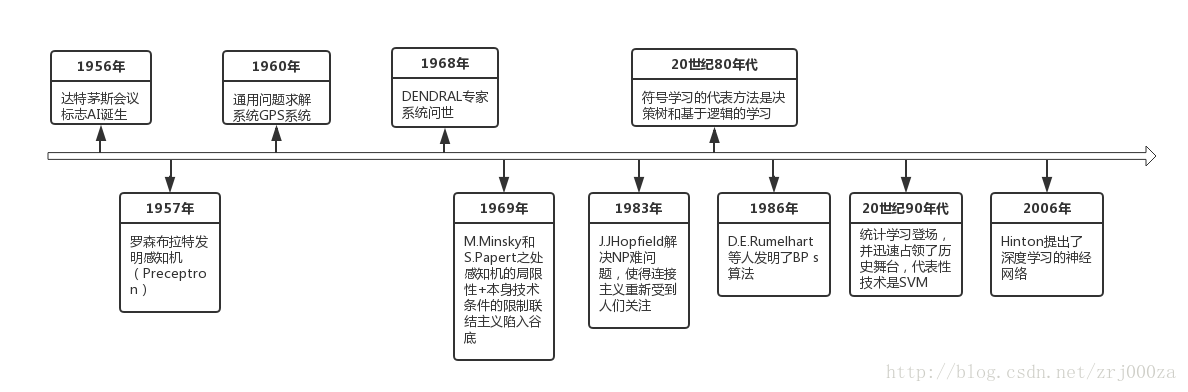
1. AI孕育期(1943-1955)
计算机器与智能的提出
a) 明斯基和同学造出第一台神经网络计算机
b) 阿兰.图灵提出图灵测试
2. AI的诞生(1956)
达特矛斯会议几个科学家(麦卡锡、明斯基、香农等)提出了人工之能这个名词,并正式有了概念。
3.热情与期望(1956-1973)
a) 西蒙提出物理符号系统
b) 萨缪尔编写西洋跳棋程序
c) 算法发明
i. 贝尔曼公式的提出:增强学习的雏形
ii. 感知器的提出:深度学习模型的雏形
d) 人工智能实验室在高校(MIT、斯坦福)的建立
e) 广泛应用于数学和NLP领域以解决代数、几何证明和英语问题
4. 第一次寒冬(1974-1980)
a) 逻辑证明器、感知器、增强学习只能够做简单的任务
b) 数学模型被发现有缺陷
c) 政府中断合作并转移资金,社会舆论压力
5. AI崛起(1980)
a) 专家系统的提出
b) BP算法的提出
6. 第二次寒冬(1987)
a) 苹果和IBM生产的台式机性能超越专家系统性能
b) 美国政府项目局否决AI为下一个浪潮
7. 现代AI(21世纪初左右)
a) 1997年IBM深蓝战胜国际象棋冠军
b) 2009年罗斯联邦理工学院的蓝脑计划成功模拟部分鼠脑
c) 大数据导致深度学习兴起
d) 2011年IBM沃森挑战智力问答节目“危险边缘”夺冠
e) 2016年阿法狗战胜人类围棋冠军
f) 2017年AI被列入各大国的战略发展规划中
2.AI通识理解
1) 基础计算能力层:云计算、GPU等硬件加速,神经网络芯片
2) 技术框架层:TensorFlow、Caffe、Theano、Torch、DMTK、DTPAR、ROS等框架或操作系统
3) 算法层(机器学习)
a) 监督学习
i. 定义:已标注的数据为老师,机器得出模型,然后输出预测数据结果
ii. 解决问题
① 回归问题
② 分类问题
iii. 算法模型
① 线性回归模型
② K-近邻算法
③ 决策树
④ 朴素贝叶斯
⑤ 逻辑回归
b) 半监督学习
i. 定义:通识使用未标注和标注的数据训练模型来进行模式识别工作
ii. 解决问题
① 垃圾信息过滤
② 视频网站分析
iii. 算法模型
① 半监督SVM(支持向量机)
② 高斯模型
③ KNN模型
④ Self-trainning
⑤ Co-trainning
iv. 优点
① 相比监督学习,节约人力成本,提高投入产出比
② 相比无监督学习,可以得到分配更高精度的模型
c) 无监督学习
i. 定义:不给机器提供已标注的数据,让机器自己对数据进行处理并输出结果
ii. 解决问题
① 关联
② 聚类
③ 降维
iii. 算法模型
① K均值算法
② 自编码
③ 主成分分析
④ 随机森林
d) 强化学习
i. 定义:机器感知环境的正状态转移时会反馈给机器的一个奖赏,使机器学习朝着正信号趋势学习,从而使累积奖赏值最大。
ii. 解决问题
① 自动直升机
② 机器人控制
③ 手机网络路由
④ 市场决策
⑤ 工业控制
⑥ 高效网页索引
iii. 算法模型
① K-摇臂赌博机(单步强化学习任务)
1. ε-贪心算法
2. Softmax算法
② 有模型学习(多步强化学习任务)
1. 基于T步累积奖赏的策略评估算法
2. 基于T步累积奖赏的策略迭代算法
③ 免模型学习
1. 蒙特卡罗强化学习
a) 同策略
b) 异策略
2. 时序查分学习
a) Q-学习算法
b) Sarsa算法
④ 模仿学习
e) 迁移学习
i. 定义:指从一个领域的学习结果迁移到另一个学习领域
ii. 解决问题
① 终身学习
② 知识转移
③ 归纳迁移
④ 多任务学习
⑤ 知识的巩固
⑥ 上下文相关学习
⑦ 元学习
⑧ 增量学习
iii. 算法模型:TrAdBoost算法
f) 深度学习
i. 定义:多层神经网络
ii. 解决问题
① 预测学习
② 语音识别
③ 图像识别
iii. 算法模型:RNN、DNN、CNN
iv. 优点
① 从特征中检测复杂的相互作用
② 从几乎没有处理的原始数据中学习低层次的特征
③ 处理高基数类成员
④ 处理未标记的数据
4) 通用技术层
a) 语音识别(ASR)
i. 概念
① 原理:输入——编码——解码——输出
② 识别方式
1. 传统识别:一般采用隐马尔可夫模型HMM
2. 端到端识别:一般采用深度神经网络DNN
ii. 远场识别
① 语音激活检测VAD:远场识别信噪比(SNR)比较高
② 语音唤醒:智能设备需要语音唤醒词来使其工作
③ 难点
1. 唤醒时间:用户发出语音到设备响应用户所花时间(目前还是略长)
2. 功耗:目前功耗并不低
3. 唤醒词:一般在3-4个字
4. 唤醒结果
a) 漏报:喊他他不应(唤醒词字数太多容易发生漏报)
b) 误报:没喊他他应(唤醒词字数太少容易发生误报)
iii. 麦克风阵列
① 背景:在复杂的背景下经常有各种噪声、回声、混响来干扰识别场景此时需要麦克风阵列 来处理杂声。
② 作用
1. 语音增强
2. 声源定位
3. 去混响
4. 声源信号的提取和分离
③ 分类
1. 线性:一维(180度)
2. 环形:二维(360度)
3. 球形:三维空间
④ 个数
1. 一般常用为2、4、6麦
2. 单麦、双麦、多麦在嘈杂环境下拾音效果差距较大
3. 5麦和8麦在安静环境下效果相当
iv. 全双工
① 单工:A和B说话,B只能听A说
② 半双工:A(中路miss了,下路注意了,完毕) B(下路收到,完毕)
③ 全双工:两人多轮对话,可插话和打断
v. 纠错:对识别的语句进行纠错
b) 自然语音处理(NLP)
i. 过程
① NLU(自然语言理解)
② NLG(自然语言生成)
ii. 难点
① 语言歧义性:意思意思(到底是什么意思,机器无法弄明白)
② 语言鲁棒性:句子多字少字错字,语法错误(这个人都经常出错,机器现在还无法搞定)
③ 知识依赖:苹果(这个到底指“水果”还是指“手机”)
④ 语境:上下文的语境分析(她走了——她到底是哪个呢)
iii. 解决方法(这个太多了就不细说了,深究的同学可自查资料)
① 规则方法
② 统计方法
③ 深度学习
④ 关联方法
iv. 应用
① 句法语义分析
② 信息抽取
③ 文本挖掘
④ 机器翻译
⑤ 信息检索
⑥ 问答系统
⑦ 对话系统
c) 语音合成(TTS)
i. 实现方法
① 拼接法:
1. 定义:从事先录制的大量语音中,选择基本单位(音节、音素)拼接而成,为了连贯性 常采用双音子(一个因素的中央倒下一个因素的中央)作为单位。
2. 优点:语音质量较高
3. 缺点:数据库较大,一般需几十小时的成品语料,企业级商用的话需5万句费用在几百 万。
② 参数法:
1. 定义:根据统计模块来产生每时每刻的语音参数,然后将参数转化为波形,主要分三个 模块:前端处理,建模和声码器。
a) 这句话的语气语调,节奏,韵律边界,重音,情感
b) 拼接法和参数法,都有前端处理,区别在于后端声学建模方法。
2. 优点:个性化的TTS大多是用参数法可节约时间成本
3. 缺点:质量比拼接法差一些,因为受制于发生算法,有损失。
ii. 评判标准(评判TTS系统的好坏)
① 主观测试:人为评测(人为来听)
② 客观测试:系统评测(机器评测)
iii. 瓶颈和机会
① 数据匮乏(可用的语音数据)
② 人才匮乏:TTS人才相比于AI中的NLP和CV类人才太少
③ 产品化难度高
1. 用户预期场景较复杂
2. 技术现在还有较多难点
3. 细节设计还需较多斟酌
④ 商业化压力
1. 项目周期较长(这个需要长时间的数据和技术的积累与沉淀)
2. 细分场景上的切入目前还处于早期阶段,试错成本较高
d) 计算机视觉(CV)
i. 发展阶段(四个阶段)
① 马尔计算视觉阶段
1. 计算理论
2. 表达和算法
3. 算法实现
② 主动和目的视觉阶段
③ 多视几何和分层三维重建阶段
1. 多视几何
2. 分层三维重建
3. 摄像机自标定
④ 基于学习的视觉阶段
1. 流形学习
2. 深度学习
ii. CV应用的处理过程
① 成像
1. 定义:模拟相机原理(怎样把照片的质量进行提升)
2. 影响图片因素
a) 光照影响
i. 从产品角度控制:可以通过提醒来改变用户的使用场景;通过升级或变更硬件设施来 提升产品的体验
ii. 从算法角度控制:利用算法对图片进行处理来提升图片的质量
b) 模糊
i. 运动模糊:人体、车辆、摄像头的移动造成
ii. 对焦模糊:摄像头的距离、质量和天气等因素造成
iii. 低分辨率差值模糊:小图放大和摄像头硬件等设备造成
iv. 混合模糊:多重模糊存在
c) 噪声、分辨率
② 早期视觉
1. 定义:图片的处理加工过程
2. 图像分割
3. 边缘求取
4. 运动和深度估计
5. 图像拼接
6. 目前问题
a) 结果不精确
b) 需要长时间的知识沉淀
③ 识别理解
1. 定义:把一张图片对应到一个文字、一张照片或标签
2. 标签
a) 越精确对模型越有利,但数据就会越少
b) 主观因素影响
c) 细分标签
3. 数据优化
iii. 研究内容(此部分还未总结完,感兴趣的可自己探寻)
① 空间视觉
② 物体视觉
iv. 典型物体表达理论
① 马尔的三维物体表达
② 基于二维的图像物体表达
③ 逆生成模型表达
v. 应用发展趋势
① 人脸识别
② 图片搜索
③ 个性化广告投放
④ 即时定位与地图构建
3.AI产品理解(此部分还未涉猎)
1) 人人都是产品经理(AI时代应该也不变)
2) 产品理解
a) NLP类
i. 对话机器人(图灵的BabyQ、微软小冰)
ii. 语音搜索(百度、谷歌)
iii. 智能语音输入法(讯飞、搜狗)
iv. 智能音箱(喜马拉雅和猎户星空的小雅音响、亚马逊的Echo)
b) CV类
i. 无人机(大疆)
ii. 医疗影像分析系统(依图科技的胸部CT智能辅助诊断系统)
iii. 无人驾驶(驭势科技、百度、谷歌)
iv. 安防
c) 机器学习类
关注我们:请关注一下我们的微信:扫描二维码
 (鼠标移入红色字)
(鼠标移入红色字)版权声明:本文为原创文章,版权归 admin 所有,欢迎分享本文,转载请保留出处!
